Scalable architecture
We design systems for growth: a solid PostgreSQL data layer, a Redis cache, and autoscaling AWS architecture that handles rising load without a rewrite.
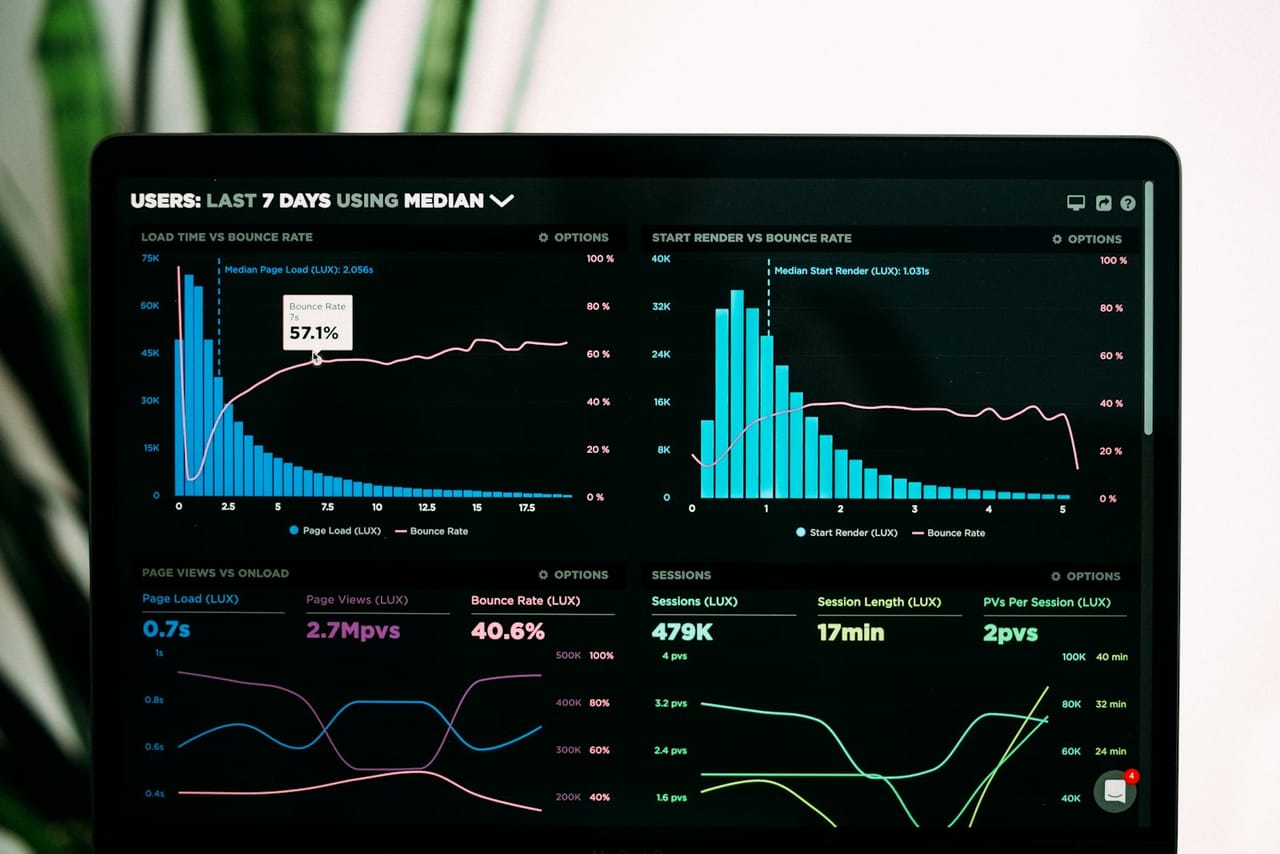
A data layer that grows with you
The database is usually the first thing to strain under load. We design the schema and queries for the access patterns you actually have, add read replicas to spread heavy read traffic, and index deliberately rather than hoping. Getting the data layer right is what lets the rest of the system scale, because no amount of extra compute fixes a slow query.
- Schema and indexes for real access patterns
- Read replicas for heavy reads
- Queries tuned, not guessed

Caching where it earns its place
The fastest query is the one you never run. We add a Redis caching layer for hot data and expensive computations, with sensible invalidation so users still see fresh results. Caching is applied where the numbers justify it, not everywhere by reflex, so the system gets faster without becoming hard to reason about.
- Redis for hot data and heavy work
- Sensible cache invalidation
- Applied where it actually helps

Compute that scales with demand
We run services on AWS with autoscaling configured to the way your traffic actually moves, so capacity follows demand instead of sitting idle or running out. Background and async work is kept off the request path so spikes do not stall the user-facing parts. The aim is a system that absorbs a busy day without anyone having to intervene.
- Autoscaling tuned to real traffic
- Async work off the request path
- Capacity that follows demand
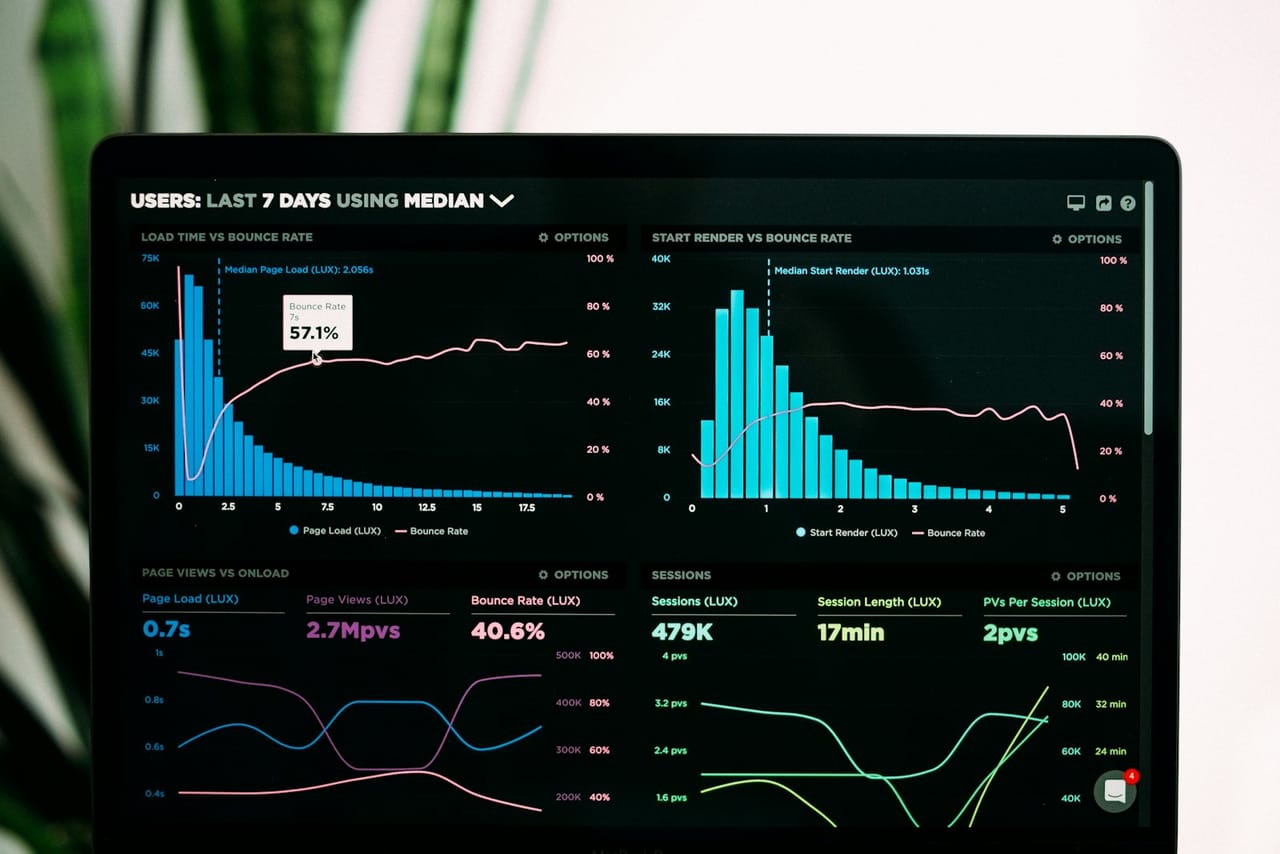
Tested and watched, not hoped for
Scalability you cannot measure is just a guess. We load test the parts that matter before launch and put monitoring in place so you can see how the system behaves as it grows. When a bottleneck appears, the metrics point straight at it, so you scale the thing that is actually constrained rather than throwing money at the whole stack.
- Load testing before launch
- Monitoring on the metrics that matter
- Scale the real bottleneck
Built to scale across the stack
We apply this to Django and FastAPI backends, with microservices where the workload calls for it. See why teams choose us over an agency.
Scalability questions
We build for the load you can reasonably expect, with clear places to scale when you need to: read replicas, caching, and autoscaling. We avoid adding complexity for traffic that may never arrive, and load test the parts that matter so decisions are based on data.
That is what autoscaling, caching, and keeping heavy work off the request path are for. We load test ahead of launch and add monitoring so spikes are absorbed and any bottleneck is visible.
Yes. We profile where it is slow, fix the real bottlenecks in the data layer and compute, and add caching and replicas where they help, rather than rewriting from scratch.
Let's build, scale, or automate it.
Hire a full senior team or a single specialist across frontend, backend, AWS, DevOps, and AI. You work directly with the engineers, not an account manager.